Chapter 6 Introduction: Transfer Learning for NLP
Authors: Carolin Becker, Joshua Wagner, Bailan He
Supervisor: Matthias Aßenmacher
As discussed in the previous chapters, natural language processing (NLP) is a very powerful tool in the field of processing human language. In recent years, there have been many proceedings and improvements in NLP to the state-of-art models like BERT. A decisive further development in the past was the way to transfer learning, but also self-attention.
In the next three chapters, various NLP models will be presented, which will be taken to a new level with the help of transfer learning in a first and a second step with self-attention and transformer-based model architectures. To understand the models in the next chapters, the idea and advantages of transfer learning are introduced. Additionally, the concept of self-attention and an overview over the most important models will be established
6.1 What is Transfer Learning?
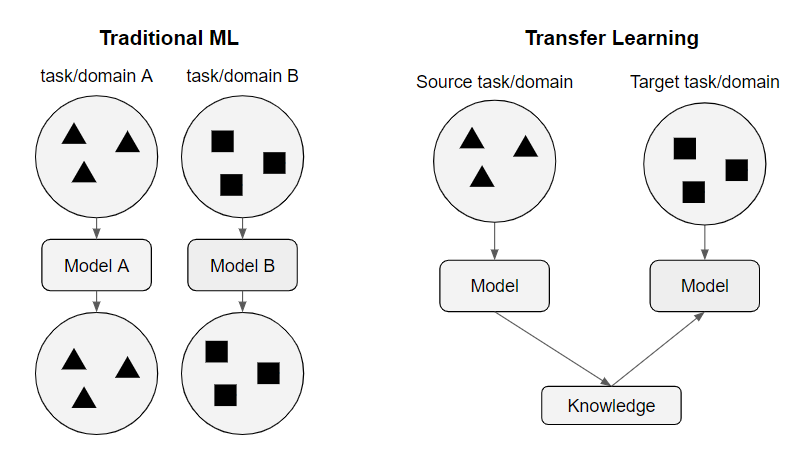
FIGURE 6.1: Classic Machine Learning and Transfer Learning
In figure 6.1 the difference between classical machine learning and transfer learning is shown.
For classical machine learning a model is trained for every special task or domain. Transfer learning allows us to deal with the learning of a task by using the existing labeled data of some related tasks or domains. Tasks are the objective of the model. e.g. the sentiment of a sentence, whereas the domain is where data comes from. e.g. all sentences are selected from Reddit. In the example above, knowledge gained in task A for source domain A is stored and applied to the problem of interest (domain B).
Generally, transfer learning has several advantages over classical machine learning: saving time for model training, mostly better performance, and not a need for a lot of training data in the target domain.
It is an especially important topic in NLP problems, as there is a lot of knowledge about many texts, but normally the training data only contains a small piece of it. A classical NLP model captures and learns a variety of linguistic phenomena, such as long-term dependencies and negation, from a large-scale corpus. This knowledge can be transferred to initialize another model to perform well on a specific NLP task, such as sentiment analysis. (Malte and Ratadiya 2019)
6.2 (Self-)attention
The most common models for language modeling and machine translation were, and still are to some extent, recurrent neural networks with long short-term memory (Hochreiter and Schmidhuber 1997) or gated recurrent units (Chung et al. 2014). These models commonly use an encoder and a decoder archictecture. Advanced models use attention, either based on Bahdanau’s attention (Bahdanau, Cho, and Bengio 2014) or Loung’s attention (Luong, Pham, and Manning 2015).
Vaswani et al. (2017) introduced a new form of attention, self-attention, and with it a new class of models, the . A Transformer still consists of the typical encoder-decoder setup but uses a novel new architecture for both. The encoder consists of 6 Layers with 2 sublayers each. The newly developed self-attention in the first sublayer allows a transformer model to process all input words at once and model the relationships between all words in a sentence. This allows transformers to model long-range dependencies in a sentence faster than RNN and CNN based models. The speed improvement and the fact that ``individual attention heads clearly learn to perform different tasks’’ Vaswani et al. (2017) lead to the eventual development of Bidirectional Encoder Representations from Transformers by Devlin et al. (2018). BERT and its successors are, at the time of writing, the state-of-the-art models used for transfer learning in NLP. The concepts attention and self-attention will be further discussed in the “Chapter 9: Attention and Self-Attention for NLP”.
6.3 Overview over important NLP models
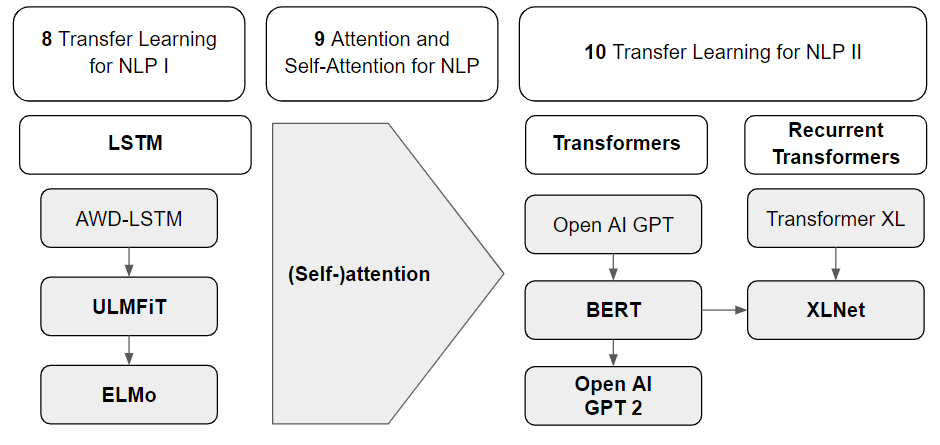
FIGURE 6.2: Overview of the most important models for transfer learning
The models in figure 6.2 will be presented in the next three chapters.
First, the two model architectures ELMo and ULMFit will be presented, which are mainly based on transfer learning and LSTMs, in Chapter 8: “Transfer Learning for NLP I”:
ELMo (Embeddings from Language Models) first published in Peters et al. (2018) uses a deep, bi-directional LSTM model to create word representations. This method goes beyond traditional embedding methods, as it analyses the words within the context
ULMFiT (Universal Language Model Fine-tuning for Text Classification) consists of three steps: first, there is a general pre-training of the LM on a general domain (like WikiText-103 dataset), second, the LM is finetuned on the target task and the last step is the multilabel classifier fine tuning where the model provides a status for every input sentence.
In the “Chapter 10: Transfer Learning for NLP II” models like BERT, GTP2 and XLNet will be introduced as they include transfer learning in combination with self-attention:
BERT (Bidirectional Encoder Representations from Transformers Devlin et al. (2018)) is published by researchers at Google AI Language group. It is regarded as a milestone in the NLP community by proposing a bidirectional Language model based on Transformer. BERT uses the Transformer Encoder as the structure of the pre-train model and addresses the unidirectional constraints by proposing new pre-training objectives: the “masked language model”(MLM) and a “next sentence prediction”(NSP) task. BERT advances state-of-the-art performance for eleven NLP tasks and its improved variants Albert Lan et al. (2019) and Roberta Liu et al. (2019) also reach great success.
GPT2 (Generative Pre-Training-2, Radford et al. (2019)) is proposed by researchers at OpenAI. GPT-2 is a tremendous multilayer Transformer Decoder and the largest version includes 1.543 billion parameters. Researchers create a new dataset “WebText” to train GPT-2 and it achieves state-of-the-art results on 7 out of 8 tested datasets in a zero-shot setting but still underfits “WebText”.
XLNet is proposed by researchers at Google Brain and CMU(Yang et al. 2019). It borrows ideas from autoregressive language modeling (e.g., Transformer-XL Dai et al. (2019)) and autoencoding (e.g., BERT) while avoiding their limitations. By using a permutation operation during training, bidirectional contexts can be captured and make it a generalized order-aware autoregressive language model. Empirically, XLNet outperforms BERT on 20 tasks and achieves state-of-the-art results on 18 tasks.
References
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. 2014. “Neural Machine Translation by Jointly Learning to Align and Translate.” arXiv Preprint arXiv:1409.0473.
Chung, Junyoung, Çaglar Gülçehre, KyungHyun Cho, and Yoshua Bengio. 2014. “Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling.” CoRR abs/1412.3555. http://arxiv.org/abs/1412.3555.
Dai, Zihang, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V Le, and Ruslan Salakhutdinov. 2019. “Transformer-Xl: Attentive Language Models Beyond a Fixed-Length Context.” arXiv Preprint arXiv:1901.02860. https://arxiv.org/abs/1901.02860.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” CoRR abs/1810.04805. http://arxiv.org/abs/1810.04805.
Hochreiter, Sepp, and Jürgen Schmidhuber. 1997. “Long Short-Term Memory.” Neural Computation 9 (8). MIT Press: 1735–80.
Lan, Zhenzhong, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. “Albert: A Lite Bert for Self-Supervised Learning of Language Representations.” arXiv Preprint arXiv:1909.11942.
Liu, Yinhan, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “Roberta: A Robustly Optimized Bert Pretraining Approach.” arXiv Preprint arXiv:1907.11692. https://arxiv.org/abs/1907.11692.
Luong, Minh-Thang, Hieu Pham, and Christopher D Manning. 2015. “Effective Approaches to Attention-Based Neural Machine Translation.” arXiv Preprint arXiv:1508.04025.
Malte, Aditya, and Pratik Ratadiya. 2019. “Evolution of Transfer Learning in Natural Language Processing.”
Peters, Matthew E., Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. “Deep Contextualized Word Representations.”
Radford, Alec, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. “Language Models Are Unsupervised Multitask Learners.”
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” In Advances in Neural Information Processing Systems, 5998–6008.
Yang, Zhilin, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. “XLNet: Generalized Autoregressive Pretraining for Language Understanding.” In Advances in Neural Information Processing Systems 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. dAlché-Buc, E. Fox, and R. Garnett, 5753–63. Curran Associates, Inc. http://papers.nips.cc/paper/8812-xlnet-generalized-autoregressive-pretraining-for-language-understanding.pdf.